A collaborative effort between MIT and Meta researchers has led to a new computer-vision technique that potentially allows self-driving cars to have a more comprehensive view of their surroundings, even seeing through obstacles like nearby vehicles.
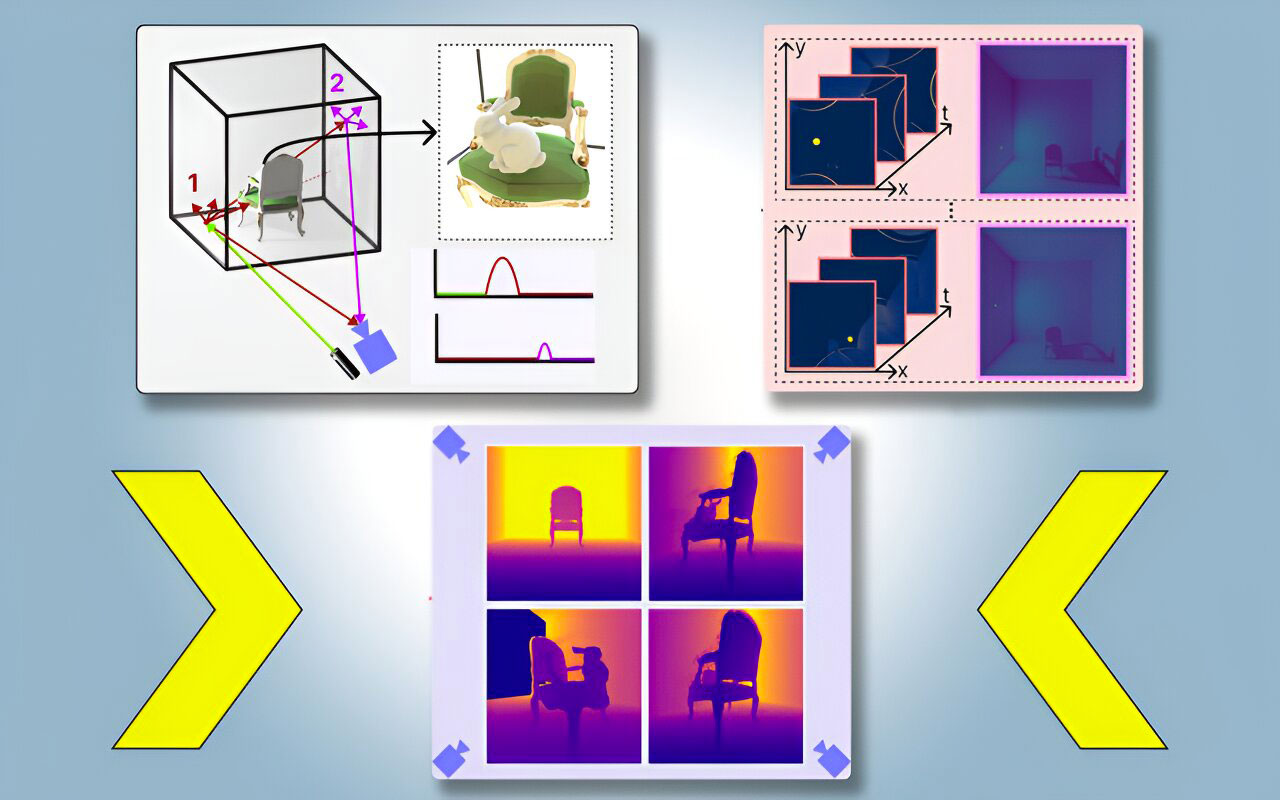
The technique involves producing complete, three-dimensional models of a scene including sections not directly visible by employing just a single camera viewpoint. This method leverages shadow analysis to infer what occupies the hidden parts of the scene. They’re calling it PlatoNeRF, inspired by the allegory from Plato’s “Republic” wherein individuals interpret reality through shadows projected on a wall.
Harnessing both lidar and machine learning, PlatoNeRF can construct more precise 3D geometries compared to some current AI methods, and it outperforms them in areas with either intense ambient light or dark backdrops where shadows are less distinct. This technology could enhance autonomous vehicle safety, and also stands to benefit AR/VR technologies by simplifying room modelling for users and assisting warehouse robots in locating objects within cluttered spaces more efficiently.
One of the core insights of this research, according to Tzofi Klinghoffer—an MIT Media Lab graduate student and lead author of the CVPR paper presenting PlatoNeRF—lies in integrating multibounce lidar and machine learning. This combination unlocks new potentials and synergizes the strengths of each discipline.
Presented at the recent Conference on Computer Vision and Pattern Recognition in Seattle, Washington, this research confronts the challenge of full 3D reconstruction from a stationary camera position. While conventional machine-learning techniques may inaccurately create non-existent aspects within concealed segments, and other methods struggling to define shapes based on shadow-casting in colour imagery might falter under certain lighting, PlatoNeRF advances by using single-photon lidar technology.
PlatoNeRF’s approach captures light bouncing multiple times within a scene, thus gathering in-depth data, including details cast by secondary shadows. The system sequentially illuminates numerous points within the scene to compile comprehensive images that reconstruct the entire space in three dimensions. Klinghoffer explains that every illumination point produces new shadows which, when combined with various light sources, helps to exclude occluded regions from the overall view, providing a clearer picture of what is actually present. Looking ahead, the MIT team seeks to explore further the benefits of tracking multiple light bounces and is poised to introduce deep learning enhancements along with incorporating color image analysis to enrich texture details in reconstructions.
DVN comment
PlatoNeRF, by integrating lidar with advanced machine learning algorithms, can generate more accurate 3D geometries than several existing AI techniques. Integrating multibounce propagation in lidar processing can enhance the characterization of objects, particularly if these objects are partially shadowed by first plane located objects. This innovation has clearly the potential to improve safety for self-driving cars and advance AR/VR technologies.